
What is a task?
A task is defined by
- Input distribution
- Label distribution
- Loss function
e.g.:
- multi-attribute classification
- multi-language handwriting recognition
Simple Multi-Task Model
Independent training within a single network, with no shared parameters
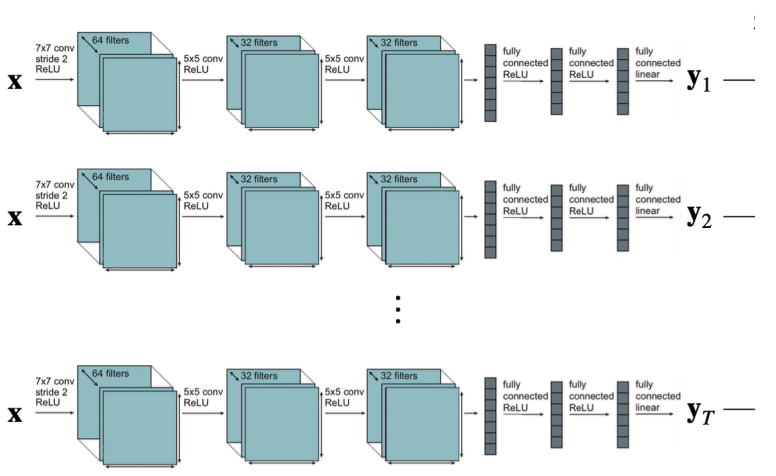
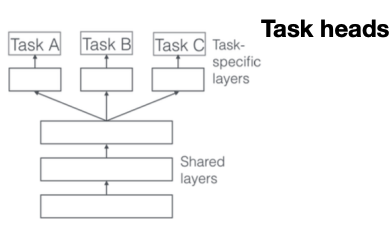
Classic Multi-Task Model
This has a shared backbone and then task-specific heads
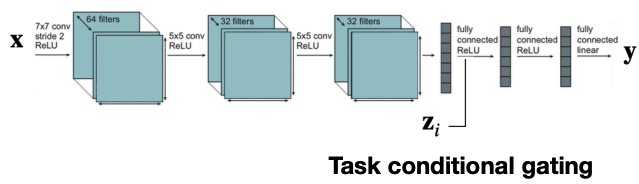
The simplest way to do MTL is one model with shared parameters Often we’d want to weight tasks differently though.
Challenges
Negative Transfer
Sometimes tasks interfere, they learn at different speeds, networks might lack capacity, or the architecture isn’t fit for sharing.
Overfitting
If we don’t share enough parameters though, each task overfits due to too few samples and too many parameters.
Transfer Learning
When we care about one target task, MTL isn’t practical: we don’t want to jointly train with 100 other tasks.
Therefore, train on source task → transfer weights → fine-tune on target
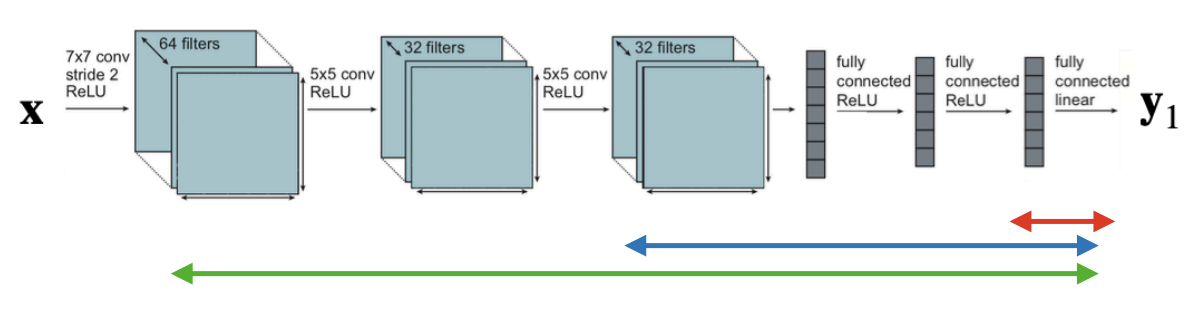
We can fine-tune in 3 ways:
- only last layer (linear probe)
- top layers
- entire model As a rule of thumb, if the target dataset is small, freeze more layers, else if it’s large we can fine-tune everything. Bigger models transfer better.
Meta-Learning
Given many tasks, how can we learn a model that adapts quickly to NEW tasks with very few samples?
 Meta-train on many tasks, then meta-testing involves 1 task with 1 or 5 examples
Meta-train on many tasks, then meta-testing involves 1 task with 1 or 5 examples
issues
Meta-learning is computationally expensive (requires higher-order gradients, nested optimization loops, etc), poor scalability to more data (trained to one-shot but struggles with 100 examples). Transfer learning actually works just as well. Meta-learning is thus beautiful theoretically but often unnecessary practically.