
paper annotated paper the transformer illustrated
RNNs are Turing complete. With enough hidden state and time, they can simulate any algorithm. It has the ability to remember previous steps, the ability to compute on sequences, etc.
Neuralizing Algorithms
Our models cannot have explicit memory, loops, or reading/writing arbitrary positions like classical algorithms, because these operations are not differentiable. To train via gradient descent, we need the differentiable version of all these operations (softmax addressing, weighted writes, etc.)
This introduces inductive bias (structure) while keeping trainability (gradients can flow).
Neural Turing Machine
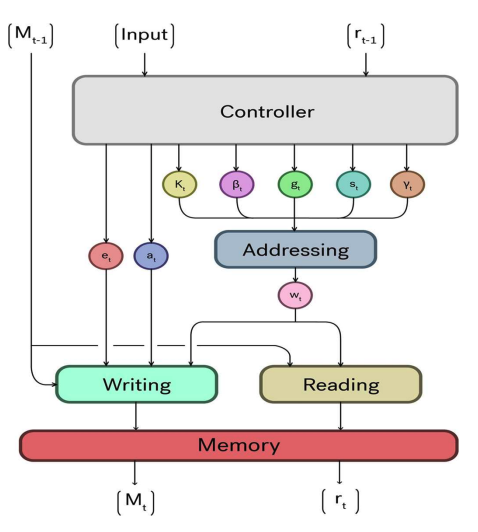
- Controller: neural network (LSTM or feedforward)
- Memory matrix: external memory
- Addressing unit: produces soft weights to determine where to read/write
- Read/write heads: differentiable versions of CPU memory operations
How to read? A hard pointer like we know it (read slot 2 exactly) wouldn’t be differentiable, so we need a soft pointer (read 70% of slot 2, 20% of slot 3, and 10% of slot 1, ignore the rest). Reading This gives us a weighed sum for a continuous, smooth mixture of memory locations, so gradients flow back through all of them.
Writing (erase and add)
= erase vector, = add vector
While LSTMs fail on long copy tasks (fails to reproduce long sequences), NTMs are able to store long arbitrary-length sequences in memory, recall them exactly and output them without degradation.
Attention Models
Attention refers to model components which focus on a part of the input or more generally on an abstract memory. The read operation from NTMs is a form of attention.
Seq2Seq without attention: encode full sentence into hidden state, decoder uses this single vector to generate the translation Seq2Seq with attention: instead of only using the last encoder state: - the decoder attends to all encoder states, - computes alignment scores , - converts them via softmax to attention weights . The context vector will be the weighted sum of these encoder states.
Attention in image captioning → use spatial CNN features as “memory slots”, then LSTM attends to specific image regions while generating words.
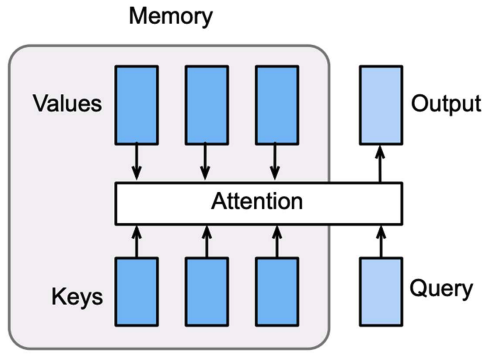 Modern attention uses Query-Key-Value stores
Modern attention uses Query-Key-Value stores
- Keys: things we can search over (metadata describing each item)
- Values: actual items we retrieve
- Query: what we use to select information, what we’re searching for
(we divide by the square root of the dimensionality of the key vectors so that doesn’t become too large)
Self-Attention
This is the core mechanism of the Transformer, where Q, K, and V all come from the same sequence. For example:
“the dog chased the cat”
when computing the representation for “chased”, self-attention lets it look at “dog”, “the”, “cat”, ”.”, and itself, “chased”. The model chooses how much each word matters.
Self-attention beats RNNs because:
- Parallelizable (all token interactions are computed once)
- Long dependencies are easy (you can attend to any other token in 1 step)
- Flexible (patterns adapt dynamically per input)
Because self-attention has no notion of order, we add positional encodings, either:
- sinusoidal encodings (fixed): encodes absolute and relative positions, allows interpolation to unseen sequence lengths. it’s smooth and continuous
- positional embeddings (learned): trainable and often works even better
Multi-Head Attention
Instead of one set of Q,K,V projections, you split into multiple “heads”:
- each head learns a different relation (syntax, semantic role, positional info, etc.) The outputs from all heads are concatenated and projected.
Transformer
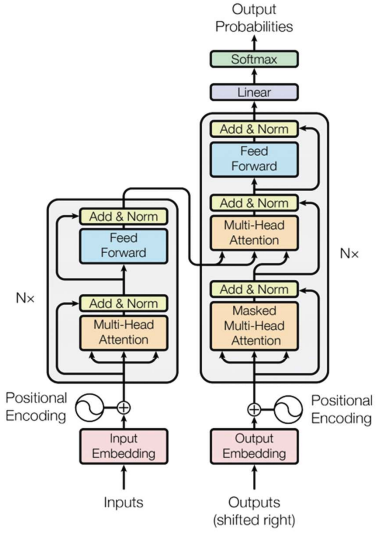 Transformer =
Transformer =
- multi-head self-attention
- positional embedding
- feedforward network (position-wise FFN)
- residual connections
- layer norm
Encoder-decoder =
- encoder: processes entire source sequence
- decoder: attends to encoder and previous tokens (masked attention)
at inference…
- decoder generates tokens auto-regressively (one token at a time, feeding its output back in)
- masking present seeing the future (GPT is unidirectional, causal self-attention)
scalability of transformers
still an issue!
- self-attention layers are more expensive than convolution or regular fully connected layer.
- no more sequence parallelization bottleneck as RNNs but each layer can be very expensive
- training of transformers is less robust than CNNs (requires complicated LR schedules and optimizers)